

Core Algorithm of Cognition

Introduction
This post describes a possible workflow based on the theory of intelligence that I am developing. This section briefly mentions the main assumptions and components of the theory.
Anything we can talk about can be considered an object - tangible or abstract, real or imaginary, existing or not (yet or already), single or groups, actions, combinations, properties, relations, collections, etc.
Objects are characterized by comparable properties. We also have ways to change those properties - actions. Objects have many properties. Each action affects only a small subset of them.
The comparability of properties differentiates this approach from many others. It enables us to be specific about operations performed by intelligence. I claim that those are comparisons. This constitutes another difference from other models that are too general in calling these operations "computations".
Trying to define intelligence, experts mention task-solving, adaptation, handling novelty, learning, planning, etc. That list is not exhaustive. Can we make it exhaustive? Can we define anything through the list of its properties or functions? Human intelligence has the answer to those questions and that is generalization. What does the list above generalize to?
Here is my definition:
Intelligence is the ability to handle (recognize, process, produce, etc.) differences.
Intelligence uses comparable properties and their ranges as basic components. Its core algorithm is a selection of the most fitting option from the available ones with respect to relevant constraints.
In this post, we will explore how this algorithm produces all the manifestations of intelligence mentioned above and what other components it uses.
Initially, this post was written as a guest post for my friend Nat. You can read it here -

This version is only slightly updated.
Main Loop
Games are often developed using the main loop that is performed as many times as the underlying hardware allows. On each iteration of the main loop, the system checks for user input, takes into account the actions of other actors, decides what intermediate results of those events are for the current iteration, and computes the positions of objects in the game world and how to reflect them on the screen. Players experience smooth video because incremental changes are very small.
Intelligence is a player in the real-time world. We may borrow the idea of the main loop to describe how intelligent agents function in their environments and interact with them.
Stages:
1. Recognize context or its change - the agent itself is a part of the context
2. Scan for signals - internal (needs, desires, etc.) or external (danger, calls for help, etc.)
3. Decide on goals/tasks or take more time
4. Scan for opportunities (what helps to achieve goals in any way)
5. Decide on the course of action or take more time
6. Action increment
We live in the real-time world of small increments but we perform and experience sequences of actions that are meaningful overall. The results of those macro events (even half-baked) deserve to be stored in memory or may affect our further actions. Therefore, our main loop should allow for the processing of signals from such macro sequences.
The core algorithm is a selection among available options. Please note that options in each case are objects (viewed broadly) of potentially different categories. We operate with those objects based on their properties.
Context
Context is a little less than everything. When we talk about a dog running in a park, it is not only the park that is the context, but also the time period. This is how you can talk about where the dog was a minute ago and where it is now. You can talk about the dog in the evening but this time the context is your memory and it can be incomplete but you will not have an opportunity to take a look and refresh your knowledge about the park. You can imagine what the dog will do in the park tomorrow, in which case the context is your imagination. When you read a book, the context is what the book described in previous pages, not the words. The same is about conversation. It is not words that make up the context. It is what stands behind those words. With words, you can describe a scene, characters, and their actions. Those are the context, not words.
There are many definitions of the context. One of them worth mentioning includes only relevant objects in the context. This begs for correction. Imagine that I want you to take a red ball. Imagine two situations - 1) there is one ball and it is red in front of us; 2) there are two balls, red and blue. Why "Take a ball!" is not enough in the second case if only relevant objects are included in the context? This example shows that irrelevant objects affect the selection of references, therefore, we have to include them in our definition and treatment of context.
Recognition of context implies that we categorize it broadly and specify details. Consider for example a "football match". That is a broad category. Teams, scores, location, etc. are the details.
How can we frame recognition as selection? We start with available options - in the case of recognition those are concepts known to us. Some concepts are more general than others. Some concepts are at the same level of generality. This implies some hierarchy of concepts and some relationships between them.
Consider the game 20 Questions. Roughly it allows us to recognize one from about a million concepts using up to 20 comparisons. Each following question depends on previous answers and covers a narrower set of concepts than previous questions. Each answer filters out about half of the remaining concepts. This game uses what I call the semantic binary search and narrows the set of fitting concepts very fast.
That differentiates this game from classifiers based on neural networks, for example, where the set of concepts doesn't change, only the probability for each concept gets updated. Another difference between these two approaches is the kinds of data used. Neural networks use whatever data they are provided and try to make decisions based on correlations that may have no explanatory power. For example, the weight of chickens increases during a season, and the points of a football team increase during a season. The game 20 Questions, on the other hand, uses what may be called defining features of each concept.
Now we can define what concepts are. Each question uses some property and a differentiating factor that breaks the continuum of possible values of that property into ranges. Each range is a concept. It may be characterized by the level of generality and by differentiating or defining factors. With respect to concepts, everything is recognized in comparison. We compare classes at the same level of generality derived from the same parent classes. It is not necessary to have only two subclasses at each level as dictated by the binary search. For example, property "color" may have 7 ranges or much more - this depends on the practical purpose of that division. Concepts are impossible without practical purposes. The "Vagueness" entry in the Stanford Encyclopedia of Philosophy puts it this way, "Where there is no perceived need for a decision, criteria are left undeveloped."
Often similarities are considered to define concepts. I claim that concepts are defined by the differences between sibling subclasses. Possible similarities of instances within each subclass are nice by-products.
The hierarchy of concepts provides one interesting opportunity - we can define rules at the class level and exceptions at the subclass level. If a rule works for some instances of a class but not for others it implies some difference between those sets of instances with respect to the action relevant to the rule. This is one of the ways to introduce differentiating factors. Note that different actions may require different division of a class into subclasses.
Definitions of concepts should mention defining factors (and relevant properties) but also optional properties so that we could query a concept, "Do you have this property?" In a similar way, we should connect a concept to all the actions to be able to answer a query, "How do you react to this action?"
Recognition of objects where we operate over static properties is different from recognition of actions. In the latter case, the idea of the main loop discussed before is used to the maximum. We observe a dynamic process with dynamic properties and as we accumulate observations we filter out possible categories of actions to finally arrive at a proper label.
Some concepts are relative or context-dependent. Before assigning labels to objects with respect to some property, we estimate the distribution, divide objects into buckets based on that distribution and only then we apply concept labels. For example, we may say that the lucky straw is long but in a different situation we may say that one route from city A to city B is short.
Signals
I don't do consciousness (interpreted as the system to receive signals) and perception (interpreted as the system to transform specific signals into evaluated properties). I start from the stage when we know the properties (color, length, weight, etc.) of an object.
One more side note. I am not a neuroscientist and I am not after replicating the brain functionality. I believe that intelligence is based on comparisons and is about differentiation. This is the essence of my model. Humans did not conquer flight by re-engineering feathers, I will not conquer intelligence by re-engineering neurons and neocortex areas.
After we have recognized the context, we may collect signals from it. These signals may be differentiated into two types - internal or external. Internal signals come from inside the agent, external ones arrive from the outside. One interesting type of internal signal is conditioning - when an agent previously programmed itself to focus on some task. It connects the agent to its past. However, the present may correct the goals of the agent.
Internal needs or desires may be classified further and in more detail and evaluated in terms of how intensive or pressing those are. External signals may require more work to recognize. Do not forget that the prior conditioning may already affect our decision-making by forcing us to skip this level.
We are social animals. We engage in both cooperative and competitive activities. Moral dilemmas in real life are not as difficult as in textbooks but still exist. Sacrifices or opportunity costs are also a part of life.
Perfect solutions are often impossible. Selection is always possible even if suboptimal or subjective.
Goals and Tasks
When we have collected the signals from the context, we may decide on what goals to proceed with. Those depend on the signals and their urgency. If only one signal feels urgent it is an easy case. If we are hungry we may decide to look for food. If we are in danger we may decide to look for shelter. For most signals, we know what goal to pursue to react to that signal. So selection works fine.
A more difficult situation is when we have to choose from several equally urgent signals. If urgency is not sufficient to make a decision we may consider other differentiating factors. Selection will work here as well, it will be just more complicated and involve more steps.
One more thing to remember is that sometimes goals may be non-exclusive and we may try to achieve several of them or follow one and achieve partial success with others.
Now please remember about comparable properties. Goals may be stated as the changes in some properties. Framing goals this way will facilitate the process of looking for solutions.
The selection of goals relies on memory. In computer science, there is one type of memory that I like to mention - key-value memory. It is easy to see how we can apply this kind of memory to the selection of goals based on signals. However, I propose to modify that kind of memory and make it key-key memory. This will enable lookups in both ways. "If I am hungry, what should I do?" "Why are you looking for food?"
Our System 1 is always ready to decide on current goals based on the signals received so far. But sometimes we may want to engage our System 2. For example, a football player may try to kick a ball from any distance in the hope of scoring a goal. But it is better to wait until the distance is short and there are no defenders in the way. If current signals allow for bleak goals only we may select the goal "wait for a better signal".
Opportunities
When we have decided on what goal(s) to pursue, we may scan the context for the second time looking for opportunities that will help us in achieving those goals. Also at this stage, we need to pay attention to any possible obstacles. Opportunities and obstacles may even affect the selection of goals or their prioritization.
It is important to recall that objects have multiple properties. An apple may be considered food if we are hungry or a weapon if someone attacks us and we need to protect ourselves. A powerful opponent may hurt us but his energy may be turned against him.
Our memory may store information about what objects may satisfy some of our needs directly or what actions and tools may change some properties in the desired way.
When we scan the context looking for opportunities we evaluate the observed objects in often non-traditional ways. We look at them through the prism of our needs. We pay attention to only those properties that are relevant to achieving our goals.
This is why representing goals as the changes in some properties is helpful. We use this information as a key to select possible options from the current context that in one way or another may help us.
Down to Earth
Our memory may already hold algorithms for achieving some goals. Those algorithms may be considered as options to select from. Opportunities and obstacles in the context will play the role of constraints. We will have to filter out those options that are hard to follow given those constraints.
Algorithms consist of multiple steps. Each step of the selected algorithm may require updates with respect to available opportunities and obstacles. Consider each step as a change in one property. When that change is achieved it may serve as a signal for starting the next step.
Our memory may contain information on how to change every property along the way and how to combine the steps in one algorithm. Complicated processes may also be considered objects with their properties - obligatory and optional. The more such algorithms we know the better it is for us - it will help us to adapt to a wider range of possible scenarios. That is why training is important - we add more options/algorithms to the set from which we will select when the need (a key to that set) arises.
Here we may touch upon the issue of the meaning of actions and processes. We may view it as the goal to be achieved. Again we need to remember about different properties that may be affected and different points of view of different people. What one may consider a meaningless action (such as asking statues for favors), the other one (Diogenes) may consider worth the effort.
Engage
Consider for example a task of making coffee in a random kitchen. For simplicity let's start with the assumption that the kitchen has everything for at least one way to achieve that goal. A coffee machine will make this task easy but if we don't have such a machine we will need to boil water somehow. We will need to find a container (a flower pot is OK), a source of water (melted ice from the fridge), a source of heat (burning whisky), etc. We will need to watch the process and avoid any failures.
Some tasks require attention to be performed well. Attention may engage all of our senses or only some of them depending on the task. Some tasks may be performed automatically after some training, but other tasks still require constant or periodic attention. In the latter case, we may say that the information required for the successful completion of the task requires conscious processing. For example, we may update the algorithm used or one of its steps. Consider a ping-pong match. We have an arsenal of hits to select from. Each hit requires knowledge of where the ball goes and how. Can we frame the trajectory prediction as a selection? We can. Based on what we observe, we will select the curve in the 3D space along which the ball will fly. Then we will select the point on that curve where we will hit the ball and the type of hit to apply.
Or we may decide to abort the execution of the algorithm in favor of some other task. For example, an injury may require a player to be taken to a hospital.
Application to Language
Our eyes can differentiate millions of shades. Languages differentiate around a dozen. It is inevitable that information encoding by language is lossy. We use language for "thinking in our head" but we can make perfectly reasonable decisions when our internal dialogue is silent, for example, when we are under stress. Communication and thought support are the two main roles of the language discussed in the literature. I propose to consider another one - language guides the attention of listeners to perceive or analyze information intended by a speaker. This way decoding information from text is coupled with observation and all the lost information is restored. So how do we refer to the real-world phenomena?
We have already discussed properties and their ranges as the basic components of intelligence. Language is created and used by intelligence, it relies on the components and algorithms of intelligence and reflects how intelligence models the world. Natural languages are intelligent.
Words refer to ranges/concepts. Any word may be easily assigned to any range. The only constraint in this case is to avoid using the same word for more than one range of the same property as this way the word will lose its differentiating capacity. It is possible, however, to refer to a group of ranges, but in this case, we are talking about a higher-level concept. But in order to be understood, a speaker who assigned a word to some range has to reach a prior agreement/convention with potential listeners that the word may be used that way. Such conventions are easier to establish in small communities than in large ones. The assignments need to pass the test of time to be accepted.
Consider synonyms and antonyms. You can now explain when words may be called synonyms - when they refer to the same range of the same property. Antonyms refer to ranges symmetrical around some "middle" range of the same property if applicable.
Each concept covers a group of objects (viewed broadly, remember?). This is achieved by observing objects with respect to the property of the concept and projecting objects onto that property in respective buckets/ranges. Note that usually contexts have limited numbers of objects. Objects have multiple properties. We may view context as a set of objects. By assigning them to different buckets according to some property we form subsets. Repeating this procedure to the subset with relevant objects but with different properties, at some point, we succeed in referring to them. When we refer to objects we need to find such an intersection of subsets that will contain only relevant objects of the context.
We may view this process differently. Objects are options. We select the fitting ones by using their properties as constraints. If one property is not enough we use another one and repeat this process to identify only relevant objects. Note that this is not a composition of a complex concept. This is context-dependent filtering/selection. Perfect use of the core algorithm of intelligence!
Now we can explain what meaning is. The meaning of a reference is objects of the context filtered by that reference. Note that meaning is context-dependent. Intelligence is very practical.
There is one problem with the above explanations. This problem is caused by the ease of assigning the same word to multiple properties (one range at a time). Words are often polysemous. How do we understand to which concept any word refers in a given phrase? The problem of ambiguity gets even more complicated if we recall that we use words for filtering and in some cases the net catches too many fishes. Which one is relevant? The use of pronouns only adds oil to the fire of ambiguity. Multiple experts consider ambiguity the real problem of natural languages. Let's clarify this.
We start the disambiguation with understanding context as residing in the objects realm. The context contains a limited number of objects. Even though objects in terms of properties are multidimensional they are not omnidimensional. When we apply a stacked reference, each word may refer to different concepts but of those concepts not all fit together in any one object from the context. In this case, we consider the meanings of each word to be the set of options and all the other words with their meanings play the role of constraints. Consider polysemous words "high" and "key" - they have many meanings each. But in the phrase "high key" those words may only refer to meanings related to voice properties. Words in the phrase constrained each other. The disambiguation among insufficiently filtered objects is resolved by clarifying questions and we know that people do that in such cases. Those questions ask to provide more filters.
The case with pronouns invites constituents to the party. Declarative sentences may have different constituents. Each of them corresponds to a question word and may be substituted by a distinct group of pronouns (viewed broadly - "there" and "then" are OK). Do you remember our idea of key-key memory? Constituents make the maximum use of that idea. Any question replaces one constituent with a corresponding question word. How do we answer questions? We consider facts in our memory and filter them using as constraints the other constituents provided in the question. Note that often we can figure out semantically what kind of answer is expected. "How high is that tree?" - we expect the measurements of length. "How high is his blood sugar?" - we expect different measurements. Words constrain each other. We can replace any constituent with a pronoun - the process is the same. It's a selection from options with respect to constraints. Semantic binary search at its best!
Ambiguity is second only to lies. But we need to understand the moving pieces involved. Talking about a speaker and a listener, we have three contexts - the shared one and two private ones for each of the parties. An incorrect phrase about the shared context cannot be considered a lie because it will be validated immediately. An incorrect phrase about the listener's private context is also not a lie, it is more of an incorrect guess. An incorrect phrase about the speaker's private context is the only one worth being called a lie but even then it needs to be believable.
And finally, let's briefly talk about mistakes. Speakers sometimes make mistakes when talking fast or if they are not native speakers and yet listeners can often understand the intended message. Natural languages are intelligent and they have decent error tolerance. If both parties to a conversation are cooperative then minor mistakes may cause smiles and confusion but the listeners will still figure out what the intention was. It is facilitated by considering the conversation history, the context, and many other factors. Similar efforts from the listeners are required for cooperative completion when listeners complete sentences for the speaker. Understanding the context and intentions behind that sentence allows listeners to do that.
Application to the ARC Challenge
The ARC Challenge was designed by François Chollet about 4 years ago. The best result of AI achieved so far is about 34%. The challenge was revived recently with the prize offered for its solution or at least some progress. You can see the announcement here -
The idea of a challenge is to solve problems where a machine needs to figure out the transformation rules from an input array of digits to an output array of digits based on several examples provided.
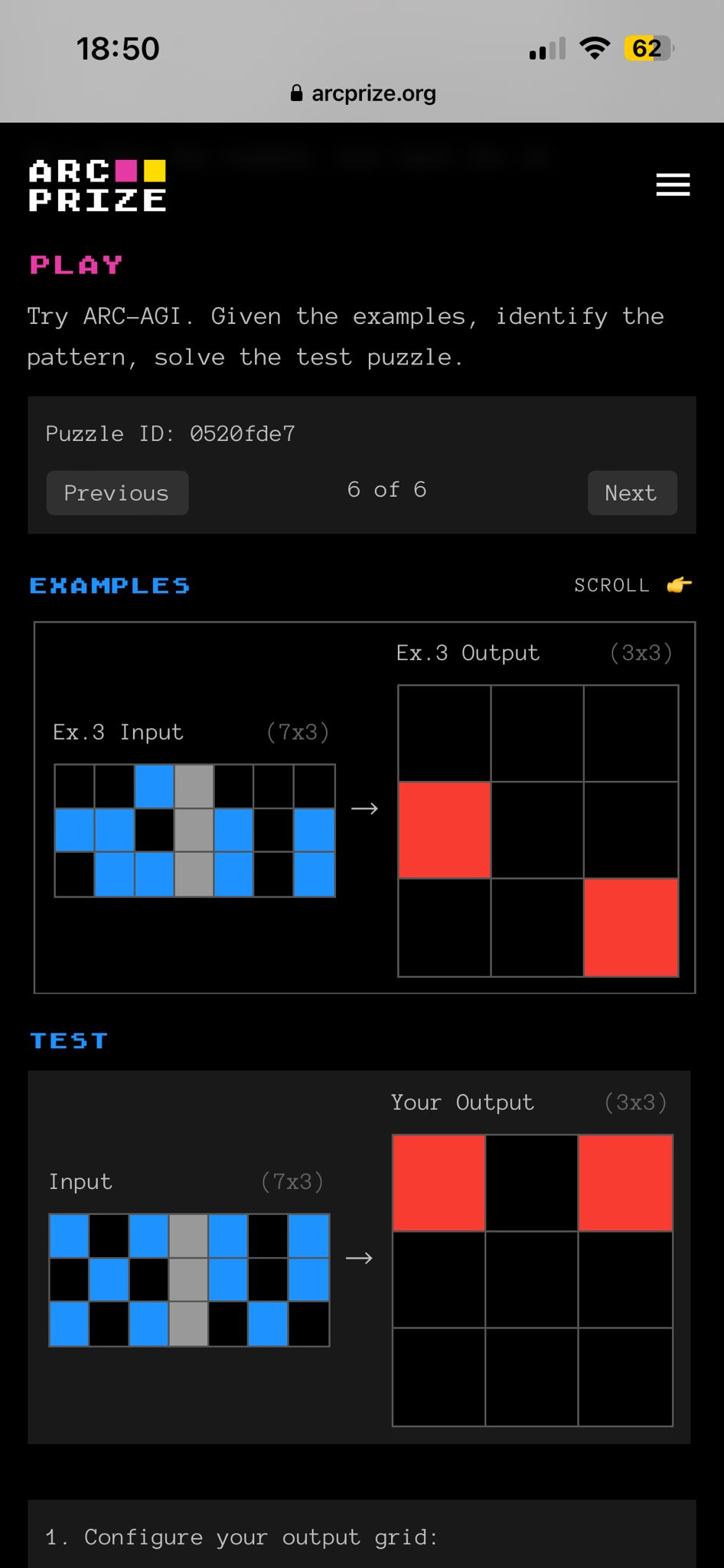
The problem with the challenge is in a large number of possible transformations. The number of primitive transformations used is not so big but they may combine in sequences of two or three. They may have parameters - colors, shapes, etc. Taken together those factors lead to considerable complexity. No wonder the challenge is tough to handle even after AI conquered the games of chess and Go.
The approach I propose in my posts may be tried for the ARC Challenge as well. Consider transformations as options. Every transformation leaves traces reflected in the properties of input and output arrays. One such property may be insufficient to filter out the unfitting hypotheses. That is why we need more of them. The same process of selection among options may be applied to figuring out the parameters of each transformation or their sequence.
The solution may constitute one of the modules of the future AGI. Note that this challenge does not test the perception. But that module will also be required. As well as many others.
Conclusion
All intelligence does is select from available options with respect to relevant constraints. But in different situations the semantics of options is different and to make it easy for us we introduce labels for these different processes - reasoning, planning, anticipation, adaptation, problem-solving, achieving goals, etc. I claim that focusing on those labels rather than on the underlying process takes us away from understanding intelligence. Hence, I decided to write this post. If you feel that something is missing, I will be more than happy to answer your questions. Now you know how to ask them and how I will answer them.
On the other hand, the wide range of terms used still allows for a lot of unclear and ambiguous explanations. Let's not forget constraints to narrow down our understanding. Let's use the guiding help of intelligence to develop a satisfying theory of what it is and how it works.