

Animals interact with the real world in all its diversity in real time and survive thanks to their perception and intelligence. Perception collects immediately available information. Intelligence processes that information, stores it in memory, and extracts hidden patterns, visible only from a distance both in space and time.
I don't do perception, but one day I might. This post is about intelligence - what metaphor best explains what it does, its mechanism, and components. Language is both a product and a tool of intelligence. Language relies on the same mechanisms. It is only natural that I will describe how language works immediately after the description of intelligence.
Introduction
On the one hand, there is a reason behind the movement of each particle out there. On the other hand, and most importantly in practice, we cannot reach the ultimate knowledge. It is computationally infeasible. We have to live by the knowledge we have so far, and we may try to grow our knowledge.
At any moment, there are patterns that we recognize consciously or subconsciously, and there are patterns that we don't. It leaves us with the islands of recognizable patterns in the sea of noise. The same is true about the persistence of patterns - there are recognizable patterns to it, and also noise. It creates a crazy dynamic in which we have to survive.
We cannot rely on noise, but we can rely on patterns. Even if we cannot explain them, while they do not fail, we may go with them. Explanations allow us to be certain that the explained patterns under some conditions will hold. Otherwise, we may be uncertain about them. Hence, we are interested in the discovery of patterns and their explanations. Ultimate explanations are unreachable, but we may search for better ones according to Deutsch and Popper.
Let us discover a better explanation for intelligence.
Better Metaphor for Intelligence
I propose to start with Heraclitus: "No man ever steps in the same river twice, for it's not the same river and he's not the same man." Everything is unique, even the same object at different moments in time. This is not what we want. Instead, we want to group objects so that the ones in the same group are interchangeable (even if distinct) and the ones from different groups are different.
Differentiation relies on comparison. How do we compare objects? It is important to keep in mind that we do not compare objects as a whole. We compare them one property at a time. Is one of them heavier? Are they of the same color? Which one is older? Note that all the other properties are ignored. But both objects must have the property used for comparison.
Whether objects have the required property and, if so, based on the value of that property, we may arrange their grouping. With groups, we may proceed as we wish - drop some, use one way or another. And this gives us our metaphor for intelligence.
Intelligence performs selection and filtering out of objects based on comparison.
Here is a quote from Goldstone, Kersten, and Carvalho, "Concepts and categorization" (2013), "Fundamentally, concepts function as filters. We do not have direct access to our external world. We only have access to our world as filtered through our concepts."
Compare (pun intended) that to the metaphor "brain is a computer." On the one hand, comparison is a kind of computation; on the other hand, when we talk about computation, the first thing that comes to mind is arithmetic operations. Addition or multiplication can hardly group objects, comparison does the job perfectly.
Comparable Properties and Concepts
My very first insight was "Language operates with nouns (objects), verbs (actions), and adjectives (properties). But objects have properties, and actions change properties. Properties are all we need." With time, I realized that the most important property of properties is their comparability.
Gärdenfors, in his 2000 book "Conceptual spaces: The geometry of thought," introduced the idea of conceptual spaces, which are essentially what I call comparable properties. The only difference is that I expand my term on both "quality dimensions" and "categories", which, for Gärdenfors, stand for primitive properties (adjectives) and complex properties or categories (nouns). Let me clarify my view.
Our senses provide us with basic information, but the real value comes from objects. We interact with them. Again, actions affect only subsets of properties, not objects in their totality. For example, "renaming" affects only the "name" property but not the others. "Moving" affects "position", but not "name." Properties are what we use, but they do not exist on their own. They are inseparable from objects. Objects are carriers of properties.
Please, be flexible about what "objects" are. Everything worth talking about may be viewed as an "object" with some properties. Not only objects around us, but also those on another continent. Not only existing ones, but also long gone or not yet created or hypothetical or imaginary. Not only physical ones, but also abstract ones. Not only individual ones, but also groups. And also actions, properties, relations, rules, facts, stories, etc.
Gärdenfors adds, "The notion of a dimension should be understood literally." Consider a comparable property as an axis with all possible values. However, do not fall for exact measurements. Point-accurate measurements do not allow for interchangeability. Ranges allow for that. As Gärdenfors puts it, "The main idea is that a property corresponds to a region of a domain of a space."
I relate ranges of comparable properties to concepts. In case of primitive properties, those are one-dimensional segments of respective axes. In case of complex properties, those are multidimensional pockets of what I call the conceptual space, which is different from what Gärdenfors calls so. My conceptual space is the combination of his conceptual spaces. His is one-dimensional, mine is multidimensional or even omnidimensional.
Let me clarify what categories (complex concepts) are. I call so a limited set of ranges of comparable properties that define what objects fit that category and what objects don't.
Similarities vs Differences
Gärdenfors mentions, "Concept learning is closely tied to the notion of similarity." Similarities serve as the basis of many theories of categorization and object recognition. I have a big problem with that. Goodman, in his 1972 piece "Seven Strictures on Similarity," was also not happy about similarities. I recommend looking at his reasons, while I will present mine.
Above, I mentioned real-time for a reason. Not only do we have to recognize a lion attacking us fast, but also make a decision on what to do and even start doing that. We would not have survived if we had based our categorization and object recognition on the use of similarities. The same applies to such techniques as Reinforcement Learning with its reward calculation and Prediction or Simulation. We just don't have time for that! Real time is a tough constraint.
Consider the prototype theory proposed by Rosch in the 1970s. In her 1978 paper "Principles of Categorization," Eleanor Rosch advocates for "cognitive economy." Further, she describes that we need to recognize a stimulus as "not only equivalent to other stimuli in the same category but also different from stimuli not in that category." Now, consider the amount of calculations required to calculate similarities to all known categories. The proposed approach is, as I love to say, natural but misleading. It is computationally infeasible.
Goldstone, Kersten, and Carvalho in their 2013 chapter "Concepts and categorization" mention that, "Rosch and Mervis (1975) were able to predict typicality ratings with respectable accuracy by asking subjects to list properties of category members, and measuring how many properties possessed by a category member were shared by other category members. The magnitude of this so-called family resemblance measure is positively correlated with typicality ratings."
Barsalou calls that "graded structure" in his paper "The instability of graded structure: implications for the nature of concepts."
I will address this shortly.
Not only that the prototype theory is computationally infeasible, but it also shows a misunderstanding of what categories are. Let me clarify again what categories are.
We start with all objects out there, and we may unite them under a generic category "Phenomenon." Recently, there has been a lot of talk about "general intelligence" and a focus on generalization. I will explain what it is shortly, but first, we need to investigate the other side of that coin - specialization. Every object generalizes to a Phenomenon, so why aren't we happy with that? Because specialization is as important, if not more, as generalization.
When we are not happy with a single category Phenomenon, we split it into two by introducing splitting criteria. It is better if those are sharp and decisive, not vague. For example, we may ask, "Is it tangible?" Based on the answer, we will have two categories - Tangible and Abstract. Please note that tangibles are called so not because of their similarities but because of their differences from abstractions.
I promise to devote a whole section to the game 20 Questions, which you should have recognized in the above paragraph, I hope. But now, please appreciate its performance. In 20 comparisons of one property each, it recognizes one of about a million categories. Compare that to the prototype theory - we need a million comparisons of multiple properties each, and then also select the best result. Differences are faster than similarities!
I propose to respect differences. I even define intelligence as the ability to handle differences.
Addressing the "graded structure", I propose to consider any category not as a final node on the specialization tree but as an intermediate one with possible further subdivisions. Those subcategories are almost always guaranteed to be distributed unevenly. Respectively, we will observe them with different frequencies. But if we see one subcategory more often but refer to it by the Category label, then this subcategory becomes a more typical representative of the Category. And the subcategory's defining features or even more prominent features may be mentioned as characteristic of the Category.
Here is a quote from Goldstone, Kersten, and Carvalho, "Concepts and categorization" (2013): "The most influential rule-based approach to concepts may be Bruner, Goodnow, and Austin’s (1956) hypothesis testing approach. Their theorizing was, in part, a reaction against behaviorist approaches (Hull, 1920) in which concept learning involved the relatively passive acquisition of an association between a stimulus (an object to be categorized) and a response (such as a verbal response, key press, or labeling). Instead, Bruner et al. argued that concept learning typically involves active hypothesis formation and testing."
I see my view as a variant of a rule-based approach to concepts. Even if such an approach is criticized by some experts.
Goldstone et al. continue, "Douglas Medin and Edward Smith (Medin & Smith, 1984; E. E. Smith & Medin, 1981) dubbed this rule-based approach “the classical view,” and characterized it as holding that all instances of a concept share common properties that are necessary and sufficient conditions for defining the concept. At least three criticisms have been levied against this classical view.
First, it has proven to be very difficult to specify the defining rules for most concepts. ...
Second, the category membership for some objects is not clear. ...
Third, even when a person shows consistency in placing objects in a category, people do not treat the objects as equally good members of the category."
I understand that "hypothesis formation and testing" take time, but they are worth it. Knowing the defining features gives clarity. But please do not confuse the clarity of categorization with a one-sided look at an object. Intelligence relies on viewing objects from multiple angles, projecting them on various dimensions. An apple may be viewed as food by a hungry person, but as a projectile weapon by a child playing the siege of a fortress. And I have already addressed the "graded structure."
Generalization
The above specialization process introduces sibling subclasses of each class based on ranges of some property. Differences between those ranges, their boundaries are the defining features of each class. And we should not forget the differences of each parent class above from its siblings. The set of defining features from Phenomenon to any given class is what category is. It's a multidimensional filter or selector.
If you want to understand generalization, you need to forget differences. According to Borges, "To think is to forget differences, generalize, make abstractions." For example, if we introduce subclasses for the class Chair based on the Color property, we may get Red Chair and Blue Chair subclasses. Forget differences in their color and you generalize back to the Chair.
The action "Run" may be specialized into "Sprint" and "Marathon." Forget differences in the distance and you generalize back to "Run."
A football match may be divided into the first and second halves. Forget the break and you generalize to the whole match. Not only time period may be generalized. Locations also can. Any sentence constituent can be generalized.
Objects are multidimensional. Depending on what properties you decide to focus, which is task-dependent, generalization may proceed via different routes. The same person may generalize to Employee or Patient or Human, for example.
Why is generalization important? At a class level, we may introduce rules. For example, boil water with tea leaves and you get tea. Why is specialization important? At a subclass level, we may introduce exceptions. Green tea leaves produce tea with a different taste compared to black tea leaves.
For details on generalization, consider taking a look at my post on Foundations of Generalization.
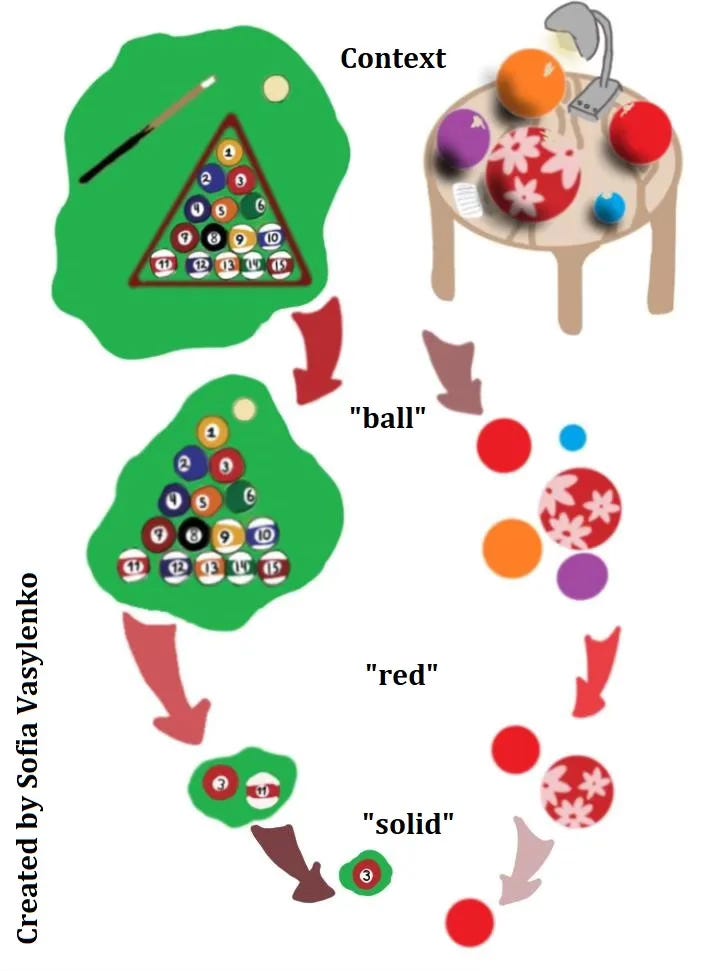
Context
We have enough variety in the world. Let's not add to it by considering everything at once. Our intelligence is fast but still limited in its processing ability. Besides, there is little practical value in objects that are unavailable.
Focusing on the current context greatly limits the number of options to consider. But we need to consider context broadly, depending on the task. It may be a park where we are walking. It may be our memory of the same park a few days back. It may be our imagination about an event at that park in the near future. It may be a screenshot or a multi-season TV show like Doctor Who. Context is about objects, their relations and interactions.
We will talk about language later, but even then context is about objects. Objects behind words, not words themselves, unless we are counting R's in "strawberry", then words are considered objects with their own properties.
Core Algorithm
Here it is - selection of the most fitting option from the available ones respecting relevant constraints.
Available options refer to the context. We cannot rely on what is not there. Relevant constraints make a difference with respect to the result. For example, a supermarket is the context, the goods there are options, and money in your wallet is the constraint.
Options and constraints depend on the task semantics. In object recognition, known categories are options, the object properties are constraints. In a detective story, suspects are options, clues and alibis are constraints.
Neither should belong or generalize to a single category. If a lion attacks a person, there are different options - attack back, run away, hide, feed the lion, pet the lion, scare the lion, etc.
Lessons from 20 Questions
Intelligence leaves hints about its mechanisms. The game 20 Questions is one such hint. I consider this game the most important for cognitive scientists. It fascinated Charles Sanders Peirce who was so occupied with rigorous logic that he missed the full potential of that game. I believe that intelligence does not rely on rigorous logic. Allen Newell claimed that "You can't play 20 questions with nature and win." I claim that we do play and do win.
Given an unknown object, we want to classify that object. The game proceeds by asking yes/no questions, constructing a binary tree. Please pay attention that at each level a question relies on a new property of the object. That property, in turn, relies on the previous answers. The use of properties makes the whole process a "semantic binary search."
There is some freedom about what questions to ask at each level. But there are also key principles to respect. We want clear, sharp boundaries between yes and no. We want the remaining categories to be split roughly in half.
The first question usually is, "Is it tangible?" An answer gives us a category: No - "Abstract", Yes - "Tangible." Please pay attention to the first lesson - we categorize Tangible phenomena not by the similarities of its instances but by the differences from its sibling category. Being tangible or not may be considered as "similarity" but it is crucial for performance to view them as difference.
Let's talk about performance. Recall the exemplar theory. It explains categorization via comparing the similarities of an unknown object to the stored exemplars of each category. You may also recall Fodor's idea about atomic concepts. Imagine you know 1 million categories. If each category is atomic and defined by the similarities of its instances, recognition will be O(N) and take 1 million comparisons multiple properties each and selection of the category with the best results. If a category is defined by differences from its sibling category, as in the game 20 Questions, then recognition will be O(logN) and take up to 20 comparisons 1 property each with no need to select a winner in the end.
Think about atomic concepts. Apples are different from peaches, from fruits, from hammers, from galaxies, from democracy. But it looks like there are differences to differences. Concepts cannot be independent. With respect to concepts, everything is recognized in comparison. Because of that, concepts should not be considered in isolation. Always take into account a parent category, the defining feature, and a sibling category. Intelligence leaves hints. Please pay attention to how dictionaries define words - C is P but with D (concept is parent with difference (from other parent instances that fall into the sibling category)). In fact, there may be many sibling categories - it is not "red" and "non-red" colors. Updating for that makes the procedure non-binary and even more efficient.
Here is a quote from Goldstone, Kersten, and Carvalho "Concepts and categorization" (2013), "One of the risks of viewing concepts as represented by rules, prototypes, sets of exemplars, or category boundaries is that one can easily imagine that one concept is independent of others. For example, one can list the exemplars that are included in the concept bird, or describe its central tendency, without making recourse to any other concepts. However, it is likely that all our concepts are embedded in a network in which each concept’s meaning depends on other concepts, as well as on perceptual processes and linguistic labels. The proper level of analysis may not be individual concepts, as many researchers have assumed, but systems of concepts. The connections between concepts and perception on the one hand and between concepts and language on the other hand reveal an important dual nature of concepts. Concepts are used both to recognize objects and to ground word meanings. Working out the details of this dual nature will go a long way toward understanding how human thinking can be both concrete and symbolic."
The game 20 Questions constructs a specialization/generalization tree of concepts showing their interdependencies.
So, what is a category? It is an important question. Many consider that categories stand for objects. It is not so. Any category is defined by a set of defining features (answers in the game 20 Questions) but that set does not exhaust the object's properties - there are many more features. Some features are immediate - we can ask that category about them and differentiate further. Some features are distant, for example, we cannot ask Tangible about taste, for that we need to go down to Edible. Well, children try to eat/taste everything, but for efficiency, it is meaningful to delay using that property for differentiation.
In terms of properties, objects are multidimensional. But note that recognition uses only a subset of those properties. Hence, recognition is a dimensionality-reducing procedure. Actions affect only a subset of properties ("rename" affects the "name" property but not the "weight" property, for example) - another example of dimensionality reduction. Linguistic references are also reducing dimensionality. Dimensionality reduction, along with semantic binary search, makes cognitive functions efficient.
The game 20 Questions relies on the specialization procedure, introducing differences and moving down the tree. For example, it breaks the Fruit category into multiple categories - Apples, Peaches, etc. What happens when we consider Apples and Peaches and decide to ignore the differences between them? We will generalize to the Fruit category. Consider the Furniture category. We may break it down by the Function property or by the Material property or by the Color property. By selecting the property differences in which to ignore, we may generalize differently.
Consider now the general algorithm of the game. It starts with a set of possible categories. It proceeds by filtering the set on the basis of properties of a given object (the game can be adapted to actions or anything else worth categorization). It stops at a desired level. We may generalize this algorithm to any cognitive function or task. We need to consider only available options because of the real-time limitations. If those limitations are relaxed, the set of options may be expanded by transporting, producing, buying, creating additional ones.
Given the tree, which we can traverse up (generalization) and down (specialization), we can add rules at each category level and exceptions at subcategory levels.
We may map input parameters of actions to their results in terms of ranges. Differences in results will define ranges boundaries for input parameters. Intelligence leaves hints. The general rule of scientific experiments requires changing one parameter, keeping others the same, and observing the results.
The game 20 Questions is amazing! If you are a cognitive scientist, please do not repeat the mistakes of C.S. Peirce and A. Newell.
Memory
Our memory is imperfect. Here is a great quote from Eichenbaum and Cohen 2001, "When a memory is retrieved, all its fragments are put back together rarely identical to the initial experience". It looks like we use modeling and simplify a lot. With the help of schemas, we may remember only essential/obligatory aspects of some composite scene or object and later reconstruct the pieces that "most likely" could be there. Reisberg in "Cognition" mentions the study by Brewer and Treyens 1981 when participants "recalled" shelves filled with books in an academic office while books were not there.
It may remind you of defining features - those are important, the other features are not so. But those effects take time. In his 2021 book "Forgetting", Small shares an important idea that memory involves two processes - writing and deleting, remembering and forgetting.
Let's now revisit generalization. We may remember more than required at first. But later, in our dreams maybe, the forgetting mechanism will get rid of the irrelevant stuff.
Let's now consider priming (https://en.wikipedia.org/wiki/Priming_(psychology)). Exposure (even subconscious) to some signals makes them "warmed up" and if the following tasks query for something similar, then those signals "pop up" in our memory. In programming, this effect is known as "cache" memory - "browser history" or "recently opened files".
Another useful idea to borrow from programming is a key-value memory. But I propose to modify it into a key-key memory. In this case, talking about Einstein will allow us to recall the relativity theory and vice versa.
A good insight into the structure of keys is provided by context-dependent learning. Reisberg in "Cognition" mentions an illustrative study of divers studying and passing exams in a library and underwater. The results were better for those groups of participants who studied and passed exams in the same environment. Therefore, context is present in the structure of keys.
We can associate the previous observation with photos made on smartphones - they all have a timestamp and a geolocation tag. Not a bad information to include in the keys in our model. Note that along with question words "who" and "what" we also have question words "where" and "when". Having such information encoded into keys allows for a more reliable retrieval.
Why do extroverts remember better and more? Because they pay attention and are interested in all the relationships and intricate details of events around them. They actively absorb keys. No wonder that character trait was called "The Luck Factor" by Wiseman in his book.
How do we store information about relations? For example, where a fork should be relative to a plate. Recall how we instruct others, "If you face the entrance, then the car is at your left." We may store some reference point and then add some kind of polar coordinates to the other objects - ten meters to the left. Or as movies often use, "At 10 o'clock."
The story of Henry Molaison, whose hippocampus was removed to treat epilepsy, is a classic. The conclusion was that the hippocampus stores long-term memory. Does it really? That small piece of our brain?
The discovery of place cells in the hippocampus and the agile plasticity of those cells do not support the "long-term memory storing" story either. Time cells were also discovered in the hippocampus. Don't you think that storing all of our long-term memory while keeping track of time and space is a bit of a stretch for a tiny area in our brain?
On the other hand, if we forget for a second about long-term memory, focus on time and place cells, and recall about timestamps and geolocation tags in photos on our smartphones, then maybe we will return to the idea of keys for storing records in memory.
One more important use for the keys produced by the hippocampus may hint at the use of comparable properties. It is known that there are specialized areas in the brain for processing information of different modalities - visual, audio, faces, etc. If we do not store the whole "object" information in the same place, how do we know how to retrieve those pieces and stitch them back together when recalling? How do we recognize previously seen objects? IDs issued by the hippocampus may be crucial for that.
Language plays an important role in both querying memory and forming it. Reisberg in "Cognition" mentions that it was observed and confirmed that we are more likely to make mistakes remembering words that sound like other words than those that look like other words. The same is true for deaf people - they are more likely to confuse words that use similar hand shapes.
By the way, suppressing internal rehearsal, or hand movements in the case of deaf people, significantly worsens our ability to remember information presented in textual form - words, numbers, phrases, etc. This may be related to another observation that we remember better information related to us. By rehearsing, we "internalize" what we see or hear.
For details, consider taking a look at my post on Memory.
Object Recognition
We have already mentioned categorization and defining properties. Object recognition is similar to it but has to rely on sensory signals only, while categorization may use directly unobservable information like internal structure or function.
I believe that differences and the core algorithm apply to object recognition as well, but we need to attract domain experts in perception to adapt them to their needs.
Errors
Object recognition may produce mistakes. Most often, those occur when conditions are poor. In a dark room, all cats are black. Why does that happen?
The process of the game 20 Questions may help. It constructs a hierarchy of features and filters out non-fitting options. If at some level we miss a step, some non-fitting options may stay in the pool of possibilities. Also, under poor conditions, we may incorrectly answer some questions, resulting in filtering out fitting options.
Most likely, this is what happens in optical illusions, when additional features are added so as to trick our filtering process.
Intelligence is about viewing objects from different angles. Errors deserve that as well. I ask you to stop treating errors as bad. ML models train on good and bad examples. But I would go even further. There are no errors. There are results. You did not miss a shot. You learned how to hit a different target.
Causality
I love this definition from Einstein: "Insanity is doing the same thing repeatedly and expecting different results."
Please note the use of the words "same" and "different." Insanity is the opposite of intelligence, but still relies on comparisons and differences.
We have mentioned that we can add rules to the specialization/generalization tree. We can go further and construct such a tree for each action. We will treat possible results as options, while input parameters may play the role of constraints.
I do not like the idea behind RL. Instead of considering or predicting multiple possible options, calculating rewards for each of them, in real time, we only have time to select an action and go with it. How do we know what actions to select from? Each comparable property maps to actions affecting it. The goal may be viewed as a difference in some properties. Selecting by keys is fast, selecting from options using the core algorithm is fast. The only thing it does not is provision of guarantees. As I love to say, we select an action, go with it and ... as Italians say, "che sara sara" or "be it what it may."
Actions also have prerequisites. Taking those into account, we may perform planning, again applying the core algorithm. Or we may figure out the sequence of events that led to the observed results.
Reasoning
I do not like it when reasoning is reduced to logic. I love to view it as juggling with available objects and skills in our imagination, solving a task at hand. Recall that actions affect only subsets of an object's properties, like the tip of an iceberg. The reasoning is turning the iceberg, investigating its different tips.
Another component of it is the search for relevant connections. We remember a lot of information, a lot of connected facts. But it took a long time before we realized that thunders and lightnings are connected.
A useful guiding principle may involve the use of metaphors. Is river like time? Is time like money? Note how metaphors rely on properties. Or even properties of properties. Or similarities of associated actions.
Intuition
Reasoning takes a long time. Intuition is fast. It observes the current context and performs a fast selection. It is not always correct because intelligence does not guarantee the desired results. But it can be trained. Intuition fails in unfamiliar domains. Experts' intuition rarely fails in their domains.
Pointing Role of Language
Fedorenko, Piantadosi, and Gibson, in their paper "Language is primarily a tool for communication rather than thought," mention two functions of language and provide neuroscientific arguments in favor of communication.
Maybe somewhat counterintuitively, but I claim that language does not transfer information. Its role in communication is important, but still limited. I see it in guiding the attention of listeners to relevant phenomena in the current context. Essentially, language is like a pointing finger but with advanced pointing capabilities.
Michael Tomasello, in his paper "First steps toward a usage-based theory of language acquisition," mentions that utterances "express an intention that another share attention with them to some third entity." I go a bit further.
You may ask how the information is transferred during communication. It can be illustrated with a simple example. When a speaker says, "Take a seat!" what in that phrase encodes the location of a chair? Nothing. And yet any listener can "take a seat." It happens because the listeners engage their perception. Therefore, communication is a two-stage process. First, a speaker guides the listener's attention to relevant phenomena, to the source of information. Second, the listener's perception collects the required information.
If a statement looks like delivering a piece of information, it is still only a suggestion, a pointing at the possible connection between the dots. Again, the listeners' attention is guided and their critical thinking is invited to validate that proposal.
With that in mind, meaning is the pointed phenomena.
Please do not see in words what is not there. When I say "Harry Potter," some may recall the death of Dumbledore, but my phrase does not encode anything like it. Associations are responsible for that connection. People who did not hear about Harry Potter will never draw such an association.
Now let's mention what can be pointed at. Any object, if you recall what I cover by the word "object." Any rule, any fact, any story. Note that pointing at different items requires different mechanisms. Noun phrases are sufficient for pointing at objects, verb phrases point at actions. To point at rules, we need to combine different phrases and apply some grammar. To point at a fact, we need sentences. Interrogative sentences point at our desire to fill in the gaps in our knowledge or they may be a polite form of a request. Imperative sentences point at our desire for some action to be performed.
For details, consider taking a look at my post on Pointing Role of Language.
Now let's see how language achieves that.
Words and Concepts
Words are not concepts. Words only point to concepts. It is possible for the same word to point to several concepts, which makes the word polysemous. Several words may point at the same concept, which makes them synonyms. If two words point at opposite concepts of the same property, it makes them antonyms. This applies to nouns, adjectives, verbs, adverbs, even to pronouns. Of course, we may determine that after disambiguation.
One important term that I introduced is "referential flexibility." It denotes the ease of assigning new meanings to words. However, it takes two to tango. In order to use the new meaning there should be a convention, on which I agree with de Saussure, shared between a speaker and a listener about that meaning. The bigger the group the harder it is to reach such a convention. That is why small communities are more agile in coming up with new meanings of words or using new words. New meanings of existing words also have to pass the test of time, if they do not cause misunderstanding or confusion.
One good example of referential flexibility is provided in Dune by Frank Herbert. There is a scene where Jessica mentions "garment", for which she and Paul share an additional meaning - "prepare for violence". A banker participating in that conversation obviously did not catch that additional meaning. Note that Jessica and Paul would not have interpreted that word in that meaning if the banker had uttered it.

By the way, the task of squeezing a word (code word) into a conversation is interesting - it needs to be used as if with a usual meaning and the phrase should be consistent with the flow of the conversation.
Please note that the convention is also required for fixed phrases, like "kick the bucket," and for syntax. Some communities even impose conventions about the structure of longer texts, like official letters, scientific papers, screenplays, etc.
References and Context
I argue that the compositionality principle is natural but misleading. Even if we make allowance for polysemous words and fixed phrases, there is still the issue of meaning. Words point to concepts, which do not point to specific objects. Even names do not point to specific people or objects because we may easily apply any name to more than one person or object.
References point to specific objects by the use of the core algorithm mentioned above. Relevant phenomena in context have multiple properties, some of which make those phenomena stand out. Obviously, those properties depend on context. Categories filter objects well, which makes them so useful. But if category labels are not enough we are free to stack more filters by adding adjectives or by mentioning relations to other objects or interactions with those.
Stacked filters depend on context and relevant phenomena. The same phrase may mean or point to different objects in a different context. Or different phrases may point at the same object in different context. Because we are free to choose the words for references, we may refer to the same object in the same context differently.
Please note another option. Grice expected speakers to be cooperative. But often this is not the case. References may be and often are misleading or unclear.
Disambiguation
Recall that objects have multiple properties. Here is the key to solving polysemy - objects are multidimensional but not omnidimensional. The set of properties of different objects contains many properties but not all possible properties.
Consider the phrase "high key". This reference refers to one object, which should have properties that correspond to both polysemous words "high" (height, sound, blood sugar level, etc.) and "key" (locking tool, sound, programming term, etc.). Among many possible objects, only "sound" fits both.
Note that both words constrain the choice of meaning for the other. I use the term "coherence constraints" to refer to these mutual constraints. Another quote that fits here is from Firth 1957, "you shall know a word by the company it keeps." Ranges of comparable properties and coherence constraints provide the mechanism for that.
The process of disambiguating polysemous words is complicated and may well lead to confusion. Above I mentioned referential flexibility. Newly acquired meanings need to pass the test of time. If linking a word to a new meaning causes too much confusion the community may decide to use a different word for that meaning.
Consider the following example of anaphora resolution and available candidates: "Stiven saw a car. It was red. It was yesterday. It was raining." We are interested in understanding each "it". All the available candidates are provided in the first sentence, some of them implicitly. Overall, there are four "objects" mentioned - Stiven, car, day (implicitly), the event of seeing (indirectly). The property "color" is only available for "car". The "time" property is only available for "event". The "weather" property is available for "day". This example also demonstrates coherence constraints in action.
Related to anaphora is cataphora. It is when a "relative reference" is used before anything is said about an "object". For example, "Because he was in a hurry, John took a taxi". We claim that "he" provides a lot of information to include an object into our set - "person", "male". Later we add the "name" property to the entry. But the use of coherence constraints remains - "being in a hurry" is coherent with "taking a taxi".
Levesque et al. (2012) proposed to prepare pairs of sentences with small differences that affect the resolution of an ambiguity contained in them. Consider the following two sentences from that dataset:
Joan made sure to thank Susan for all the help she received.
Joan made sure to thank Susan for all the help she had given.
How should "she" be resolved in each case? Is it Joan or Susan? In my theory, I propose to keep track of expected direct/indirect objects for each action. In this case, "thank smb for smth" expects something good, to which "help" generalizes well. If she received help, she should be the subject of "thank", otherwise, she should be the direct object.
Sometimes, information from the sentence is not sufficient for disambiguation of grammatical structures and therefore constituents. Consider the example, "Visiting relatives can be annoying". Is it "visiting whom" or "visiting who"? Imagine now that the following sentence is mentioned in the context, "I don’t like the climate there." The "visit" action may change, among others, the property "exposure to climate". Note the use of anaphoric "there" and that "don’t like" resolves to the same range of the "attitude" property as "annoying". All these considerations support the version that I visited my relatives.
As an alternative, consider the following hint instead, "I don’t like when my house gets crowded." In this case, we consider "visit" as changing the property "number of people in my house". "gets crowded" means the increase in that number. Therefore, this hint supports the version that relatives visited me.
Sentences
A declarative sentence may be of one of two major types - SVC or SVO. It is either static, informing about properties of the subject, or dynamic, informing about interactions of the subject with other objects (possibly the subject itself). There are many possible constituents in a declarative sentence.
Again, analyzing a declarative sentence, we are interested in the objects referred to and additional information about them. One may talk about the truth conditions but actual references of natural languages are messy and multilayered to be simply evaluated in terms of true/false values.
Questions
Questions seek knowledge. The simplest yes/no questions just request a confirmation or refutation of a fact. More interesting are the questions that substitute one of the constituents with a question word. How do we answer such questions?
Again, we are using the core algorithm. Sentences in our memory, resolved for actual objects, are options to be filtered. The other constituents provided in the question are constraints. We need only to remember about specialization/generalization when resolving them for equality against the objects in our memory. If we find a match, we extract the answer from the found sentence. Otherwise, we answer "I don't know."
I think it is important to mention "good questions". Those are questions with well-established constituents. Imagine a prehistoric man asking, "What is a rocket?" and you answer, "It's a projectile that uses reactive propulsion to overcome gravity and reach outer space." The words "projectile, reactive propulsion, gravity, outer space" do not differentiate any constituents known to the "listener". Therefore, the answer will not sink in. As a house is built brick by brick, knowledge is added on top of the existing, known facts. You cannot add a roof before the walls.
How did I come up with the core algorithm? Thanks to questions. I first treated sentences as formulas. But answering a question breaks that metaphor, because questions are more like multiple-choice problems. We do not compute an answer, we select it from available options.
This is another reason for using ranges instead of point-accurate measurements. There is an unlimited number of points. But a limited number of ranges. Binary search is fast on limited sets.
Truth vs Lie
Above, I mentioned that a speaker and a listener have to share context to communicate efficiently. Now I will introduce private contexts. Imagine a detective interrogating a suspect. Both have private contexts - information unknown to the other. The suspect misrepresents one's private context in order to evade punishment. The detective does not mention the available evidence in order to collect more false testimonies. Both lie in order to get better off in the end.
Now, take a look at the following statement: "This text is written in Italian!" Can we call it a lie? Can I expect to get better off in the end? For example, I may hope that you will respect me more, believing that I know Italian.
I do not insist but I strongly believe that "lie" is about misreporting private context only. If the context is shared and any claims about it are easily verifiable, misreporting it makes no sense.
Language Acquisition
Babies are intelligent. They engage their core algorithm to figure out stuff from birth. They have to begin with ordering their sensory input, so it is natural that they first learn directly observable concepts. Presented with multiple red objects and hearing "red" they learn what color is and possibly many shades of the "red" range. Presented with cubes of different sizes and colors and hearing "cube" they learn what cubes are. They learn by figuring out or filtering a single common property, and ground a respective word that way.
It takes longer to figure out more involved concepts and map them to the respective words. For example, actions to verbs, abstract concepts.
Becker in "Language Acquisition and Development" mentions, "After a child has acquired (roughly) the initial fifty words, there is often (though not always) a sudden rush of word learning. This rush is like a burst of energy, or an explosion, in which the child seems to take a big step up in their word production. Typically, the first such vocabulary burst (and many subsequent ones too) is a nominal explosion, meaning that many nouns are learned in a short amount of time. But later in development, when the child has several hundred words in their productive vocabulary, there may be an explosion of verbs."
First, we see that nouns are acquired earlier than verbs. But how can we explain those "bursts"? Recall that a comparative property is an axis with ranges. It may take some time to figure out the first range and the axis, but all other ranges will go fast.
Michael Tomasello in his paper "First steps toward a usage-based theory of language acquisition" mentions, "most children also have in their early language some so-called frozen phrases that are learned as holophrases but will at some point be broken down into their constituent elements, for example, Lemme-see, Gimme-that, I-wanna-do-it, My-turn, and many others (Lieven et al. 1992).
...
She must be able either to "break down" or to "fill out" her holophrases so that she can express her communicative intentions in the more linguistically articulated way of adult speakers. Learning how to do this depends on the child's ability to comprehend not only the adult utterance as a whole, but also the functional role being played by the different linguistic elements in that whole. This is the beginnings of grammar."
Differentiation takes time. It requires multiple examples with different components, but semantic binary search does its job, and at some point, "breaking down" and "filling out" occur, and after that, the telegraphic stage begins.
Becker in "Language Acquisition and Development" mentions, "Significantly later in development (around age 2;0 to 2;6), once the child has about 400 words in their productive vocabulary, function words (like auxiliary verbs, agreement markers, certain modal verbs, the copula verb be, conjunctions, and articles) increase in number and frequency."
This means that a child starts figuring out how to point at facts. Observing facts and hearing familiar words with those function pieces, the child figures out the role of the word sequence, agreement markers, conjunctions, etc.
Becker continues, "Sometimes children’s early words are bound to the immediate context. That is, the child might use a general noun like birdie to refer to a stuffed animal bird, not to birds in general. This is known as underextension: when a word refers to a class that is smaller than the target class. ...
Opposed to underextension is a phenomenon referred to as overextension. Overextension occurs when a child takes a word’s meaning to include a larger class than in the adult grammar. ...
Overextension is usually based on some perceptual features ...
Unlike underextension, overextension errors are very common and are found crosslinguistically."
Using features, it is easy to fix both of those issues. Expanding the range will fix underextension, and introducing additional differentiating factors will fix overextension. The fact that "overextension errors are very common" is easy to explain - the formation of concepts is in the process, and many differentiating factors are yet to be added.
Becker mentions, "Together, these two problems add up to what is referred to as the mapping problem. Given the inherent variability between what we experience in the world and how we talk about those experiences with language, it’s not reasonable to think the child will know exactly which aspect of an object or situation is being labeled with a particular word without some inductive constraints."
This is exactly the reason for using the semantic binary search. On the first encounter, there are many options. On the second encounter, there are many, but different options. A simple set intersection eliminates, filters out non-fitting options. Later, when a new range for a category is mentioned, "That fruit is a peach," the category label filters out multiple options, making it easier to map the word to an object.
Becker also mentions the categorization problem, what features define a concept and how to figure out those, mentioning the prototype theory along the way. I have already addressed that, so I will not repeat myself.
Becker raises another interesting question, "Before a child can even learn what words mean, they must know that words actually can be linked to individual meanings — that is, that words (can) have the property of being referential.1 Where does this knowledge come from?"
Observing any situation, we try to store everything about it in our memory. Observing a ball and our mom pointing at it and saying "ball," we remember all those pieces along with a lot of irrelevant stuff. After multiple such scenes, we collect enough information to filter out everything irrelevant, leaving only the relevant connection.
The Baldwin and Markman (1989) experiment, which Becker describes, shows that provided a label for a novel object, "children spending extra time attending to the new object is essentially them trying to figure out which features are crucial for the meaning of the new word and perhaps trying to categorize the new object." Their following experiment showed that pointing at a novel object also caused increased attention, but linguistic labeling had additional advantages. This strengthens my suggestion that language is a pointing finger with advanced capabilities.
This is also related to forming keys in memory and storing multiple projections of that object for future recognition.
The core algorithm is powerful, but the real world provides enough complexity for language acquisition to take a long time. I already mentioned that similarity-based approaches are way slower. Imagine a situation when a lifetime is not enough to learn a language!
Growth of Knowledge
I started this post with a statement about knowledge. Let me quote Karl Popper, Conjectures and Refutations: The Growth of Scientific Knowledge (1963):
"Every solution of a problem raises new unsolved problems; the more so the deeper the original problem and the bolder its solution. The more we learn about the world, and the deeper our learning, the more conscious, specific, and articulate will be our knowledge of what we do not know—our knowledge of our ignorance. For this, indeed, is the main source of our ignorance: the fact that our knowledge can be only finite, while our ignorance must necessarily be infinite."
We cannot reach the ultimate knowledge. But we may try to dig deeper. Ranges of comparable properties may serve as a guide in that process. If for some range we do not know how to reach it, that represents a gap in our knowledge. If we observe that a novel combination of input parameters or novel actions allow us to reach some range, it increases the set of options to select from. It may also be a more efficient way under some conditions.
The core algorithm is efficient. Let's use it to facilitate the progress of science.
Hi!
Hope you are doing well.
At around 8,500 words, the piece is significantly too long for a typical Substack post. I strongly recommend breaking it into a series of shorter articles, each focused on a distinct theme (e.g. categorisation, memory, language acquisition). Readers are more likely to stay engaged with posts under 2,000 words. I quickly disconnected and it will take quite a while to read and make sense of your thesis.
The central idea—that intelligence operates via comparison and that this underpins language—is intriguing, but the argument lacks clear logical scaffolding. Key claims (e.g. “differences are faster than similarities”) are asserted rather than demonstrated, and the transitions between topics can feel abrupt.
As a linguist, I find you assertion on Grice very misguided because you do not define the scope.
It's about contributing to a conversation in a way that is oriented toward mutual understanding, assuming a shared goal of communicative success. The four maxims—Quantity, Quality, Relevance, and Manner—are guidelines that rational interlocutors are presumed to follow unless there's good reason not to.
Example: Saying “Some of the guests arrived” when you know all did violates Quantity, but might implicate that not all were welcome.
Grice himself acknowledged that violations or floutings of these maxims are not only common but essential to communication, as they generate implicatures. So the principle was never absolute.
It is really good to see that you cite several important thinkers (e.g. Gärdenfors, Goldstone, Tomasello), but references are occasionally vague or used without critical engagement. The piece would benefit from tighter integration of sources into the argument and a consistent referencing style.
I think this has has real potential if reframed as a structured series. I wish better skilled people than me wold engage with your piece as well. I would suggest you redraft starting with s short introductory post outlining the overarching thesis and then with follow-up posts on:
- categorisation;
- memory;
- object recognition;
- language acquisition;
- reference and meaning.
You more concret examples if possible, it helps with bastract claims.
Sorr this is very short and doe not address the sentral thesis. As I said above, a very long piece to read!
I will try and focus on the thesis at a later stage.
Best regards
More concrete examples, diagrams, or scenarios to support abstract claims